Est-ce qu'on peut augmenter la qualité des effets sonores des RTP grâce à la super-résolution audio ? La super-résolution audio, c'est comme de l’upscaling d’image, mais pour le son.
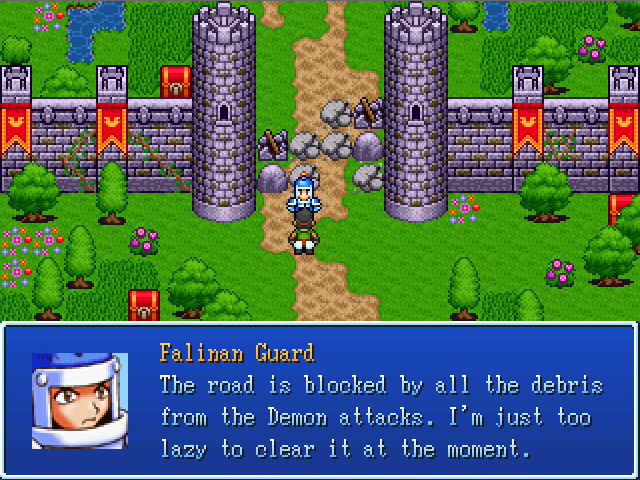
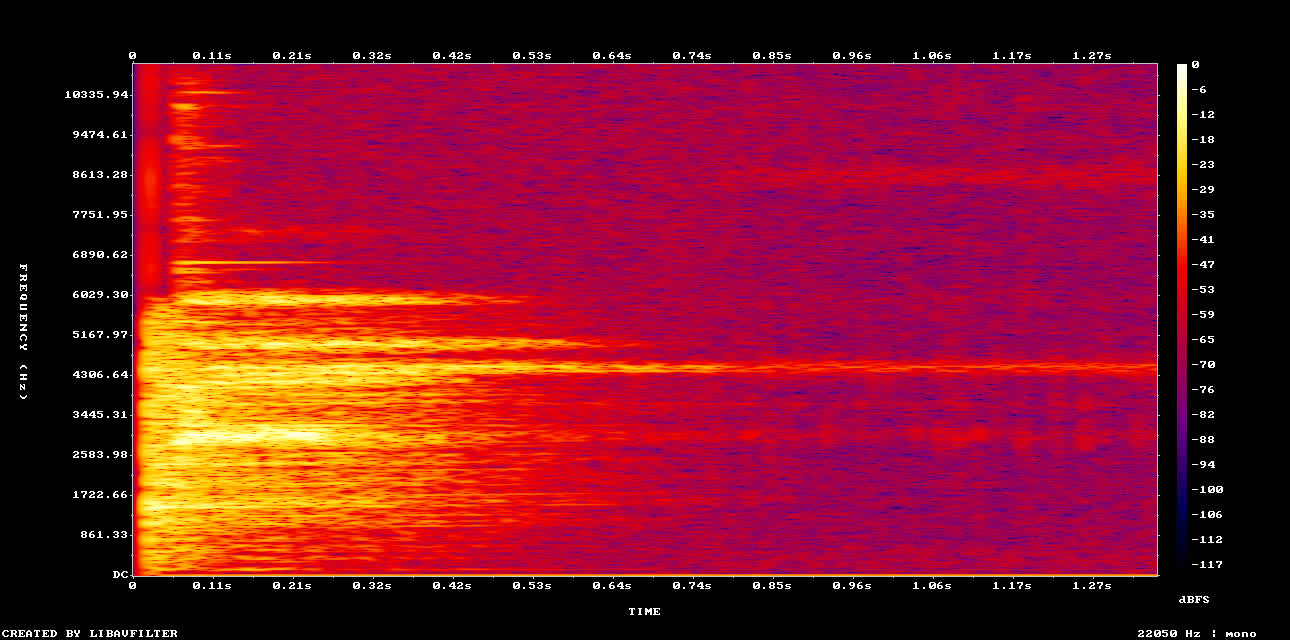
Original
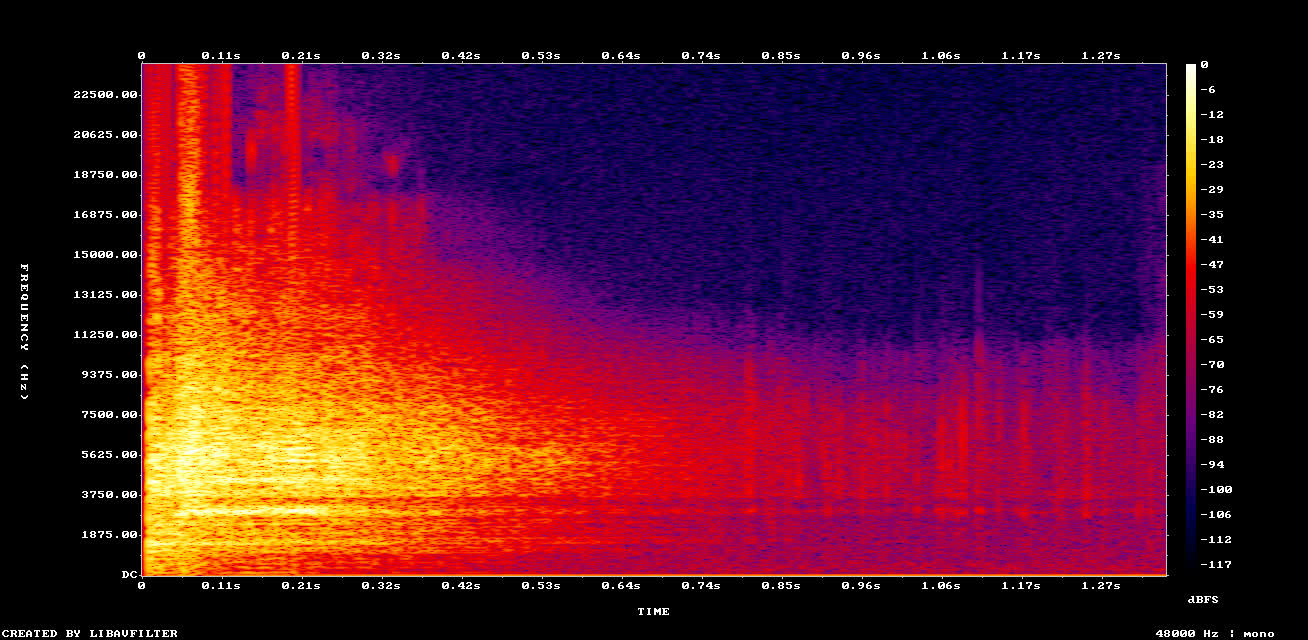
Super résolution
Pourquoi c'est difficile ? Vous pouvez agrandir une image dans Paint, mais ça n’ajoute pas magiquement des détails, ça rend juste les pixels grands et flous. C’est la même chose avec l'audio. Convertir simplement un fichier vers un plus gros format ne rajoute pas magiquement des détails. Le but est de reconstruire les détails manquants de manière plausible.
Prenons un exemple : l’effet Sword2.wav d’origine des RTP de RM2k.
Cette image est un spectrogramme : il affiche les fréquences du son (graves, aigus) au fil du temps. Les zones claires correspondent aux fréquences et aux moments les plus forts.
Le son original semble tout droit sorti d'une cassette d’un film de karaté des années 1980. C'est parce que les RTP sont encodés en .WAV, certes, mais à 22.05 kHz et 16 bits pour économiser de l'espace disque. Ca veut dire que les fréquences encodées ne vont que jusqu'à 10kHZ, alors que l'oreille humaine entend jusqu'à environ 20 kHz.
Regardez le spectrogramme : cette fois, l’échelle va jusqu’à 24 kHz. Le nouvel audio est en 48 kHz, 24 bits. C'est mieux qua la qualité CD ! À l’écoute, le son est plus brillant.
Le son n’est pas juste plus fort, égalisé différemment, ou avec de reverb. Le spectrogramme montre des fréquences manquantes reconstruites de façon logique, comme si l’on avait demandé à quelqu’un de « repeindre » les détails perdus.
Voilà. C'est ça la restauration audio. Et en gros j'ai fait ça pour tous les effets sonores des RTP.
Télécharger tous les effets sonores restaurés de RPG Maker 2000 RTP
J’ai traité les 203 effets sonores du RTP de RPG Maker 2000 pour les convertir en versions haute qualité en 48 kHz.
Comment ça marche? Le modèle de restauration UniverSR
Alors, je n’ai pas retrouvé les versions originales en haute qualité de ces fichiers. J’ai juste utilisé un modèle de machine learning.
UniverSR est un modèle de super-résolution audio développé par l’Université de Séoul en 2026. Il prend en entrée un audio de faible qualité et reconstruit une version de meilleure qualité du même son.
Pour expliquer UniverSR simplement, l’audio est d’abord transformé en image (le spectrogramme). Ensuite, le modèle reconstruit les détails à l’aide du flow matching, la même technique que pour la génération d’images IA super réalistes (comme Nano Banana ou Midjourney). Enfin, le spectrogramme est reconverti en audio.
UniverSR a été entraîné avec des données audio libres de droits (voix, musique et effets sonores). Ces audios sont dégradés afin de créer des paires d’entraînement. Le modèle regarde la version basse résolution et imagine à quoi devrait ressembler une version haute résolution.
Comment restaurer des sons avec UniverSR ?
UniverSR est open source, mais il demande quelques connaissances techniques et un GPU puissant. J’ai pu le faire tourner sur Neural Analog qui rend l'importation et le processing très simple (configuration : modèle universr-audio, mono, préréglage 4 kHz vers 24 kHz).
Le traitement a pris environ 20 minutes pour l’ensemble du pack. Ce modèle n’est pas le plus rapide, mais les résultats étaient meilleurs que les autres options automatiques que j’ai testées (AudioSR). Peut-être on peut encore améliorer les résultats avec d'autres préréglages ou retouches manuelles...
Pour Jump ou Bell on dirait qu'il y a des bruits parasites qui se sont rajouté, je me trompe ?
Je me demande ce que ça donnerait de l'entraîner au cas par cas (par ex donner en input plusieurs bêlements différents pour avoir un encore meilleur Sheep.wav)
Tu as déjà utilisé ce modèle pour d'autres besoins de restauration ?
Tout le savoir faire d'AristA dans une news. Merci !









 Merci !
Merci ! 
'%20d='M69.364%2019.146c36.687%2027.806%2076.147%2084.186%2090.636%20114.439%2014.489-30.253%2053.948-86.633%2090.636-114.439C277.107-.917%20320-16.44%20320%2032.957c0%209.865-5.603%2082.875-8.889%2094.729-11.423%2041.208-53.045%2051.719-90.071%2045.357%2064.719%2011.12%2081.182%2047.953%2045.627%2084.785-80%2082.874-106.667-44.333-106.667-44.333s-26.667%20127.207-106.667%2044.333c-35.555-36.832-19.092-73.665%2045.627-84.785-37.026%206.362-78.648-4.149-90.071-45.357C5.603%20115.832%200%2042.822%200%2032.957%200-16.44%2042.893-.917%2069.364%2019.147Z'/%3e%3c/svg%3e) Bluesky
Bluesky


